
今回の記事はAWSのS3にpythonを用いてファイルをアップロードまたはダウンロードする方法についてご紹介する記事になります。
では早速メインの記事に進んでいきます。
AWSにS3バケットを作成
ではまずはAWSですがAWSのアカウントを作成しましょう。こちらは無料でも作成可能ですし、非常に簡単なのでこちらなどを見ながら完了させてください。
コンソールに入った後に関しても上記のサイトを参考に「サービス」→「S3」→「バケット作成」→「権限付与」→「作成完了」という風な流れです。
では次にアクセスするためのユーザーを設定します。
AWSの接続設定
AWSには「IAM」というサービスがあります。このサービスは権限を付与したユーザーを作成することができます。このユーザーでとりあえずS3バケットにFull権限のユーザを作成してそのユーザのアクセスキーとシークレットキーを作成すれば良いと思われます。
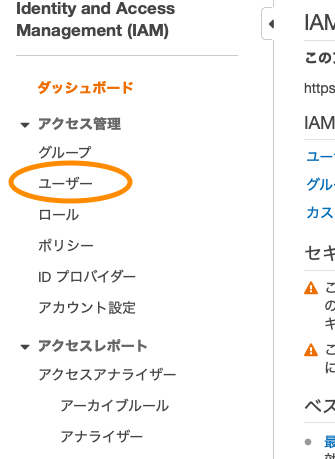
まずはサービスからIAMをクリックする。その後ユーザをサイドバーから入力を行うをクリックします。
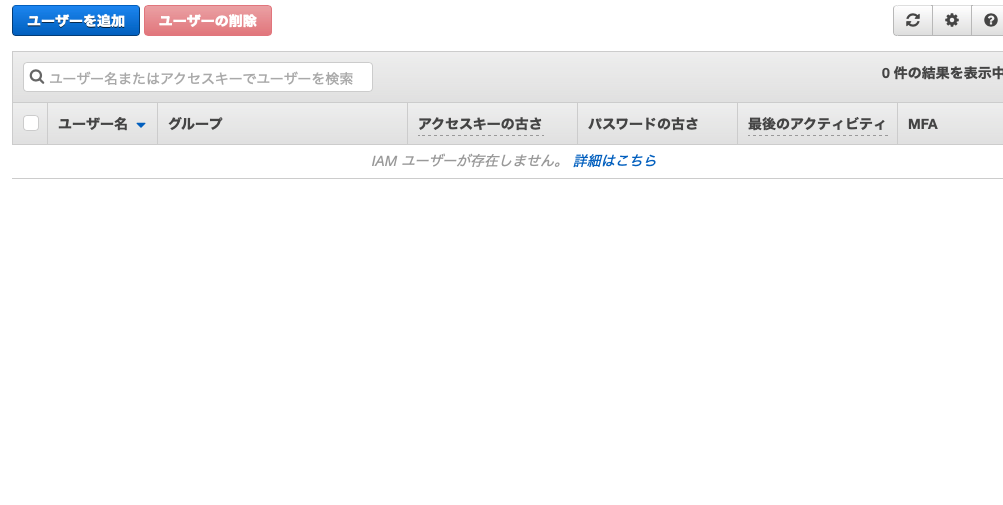
ユーザをクリックします。
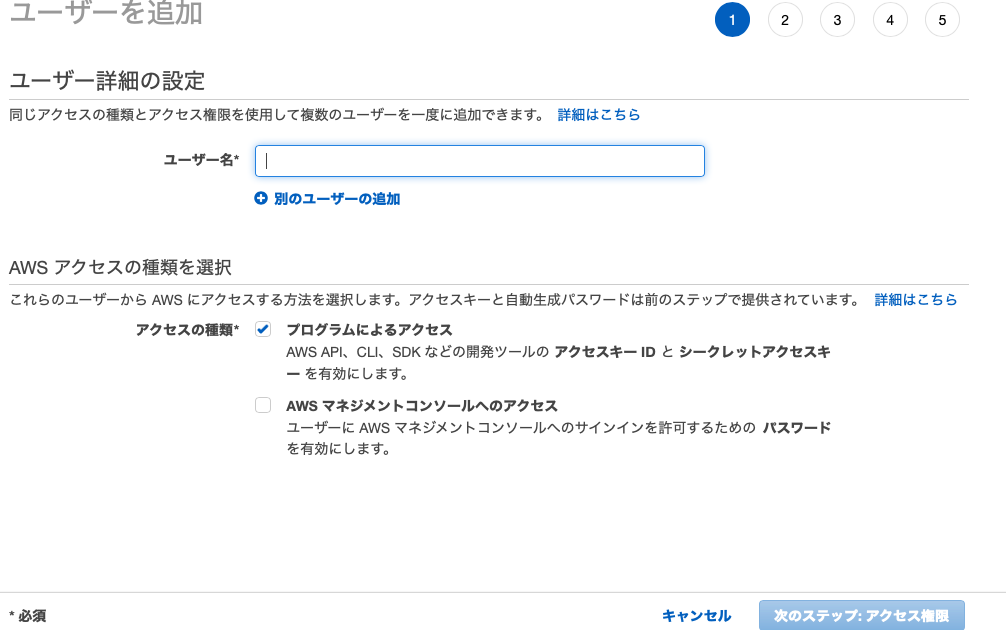
プログラムによるアクセスの許可をチャックし、ユーザ名はなんでもOKです。「testuser」でOKです。
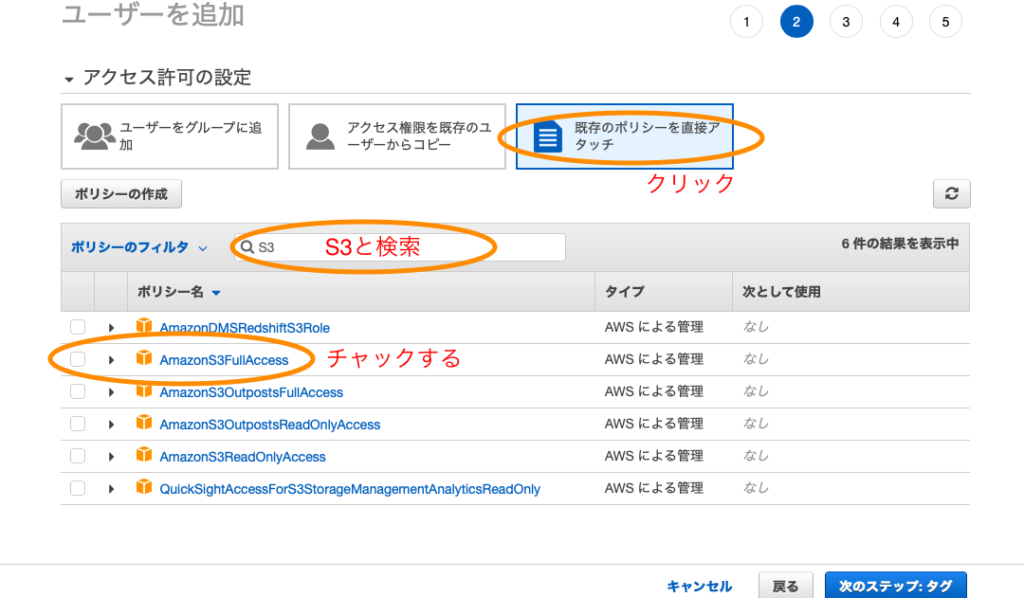
上記のように既存のポリシーをクリックし、ポリシーを検索するためにフィルターにS3とクリックします。するとFullAccessが表示されるのでそこにチェックをつけ、次のタグ作成に進みます。タッグに関しては私は空欄のままにして次に進みユーザを作成しました。
ユーザを作成した際にアクセスキーとシークレットキーが表示されるのでこのキーをメモっておきましょう。
PCでのキーの保存
先ほど作成したアクセスキーとシークレットキーを自身のPCに保存します。ターミナルで下記を実行します。
pip install boto3
pip install awscliこれで下記の情報を求められるので下記を入力することでキーの登録が完了します。
AWS Access Key ID [None]:あなたのAccess Key
AWS Secret Access Key [None]:あなたのSecret Access Key
Default region name [None]:regionのコード値(だいたいap-north...かな?)
Default output format [None]jsonAWSのS3にファイルアップロード
import boto3
s3 = boto3.resource('s3')
bucket = s3.Bucket('[自身で設定したバケット名]')
bucket.upload_file('upload/test.txt', 'test.txt')AWSのS3からファイルダウンロード
import boto3
s3 = boto3.resource('s3') #S3オブジェクトを取得
bucket = s3.Bucket('[自身で設定したバケット名]')
#先ほどのアップロードしたファイルをダウンロードしてくる
bucket.download_file('upload/test.txt', '[自身のPCの保存したいpathを記載する]')
コメント
[…] ユーザー名は適当でOKで、その下のアクセス方法ですがプログラムによる操作(例えば「PythonでS3にファイルアップロード」など)を行う場合は写真のように上のチェックを入れます。 […]