
今回の記事はswiftライブラリの中のOCRライブラリ「SwiftyTesseract」についての記事になります。
正直そのままの使用では日本語の読み取りは愚か、その文字領域のみを取り出すことも難しいという悲惨な結果に、、
自身で識別対象の画像を取集してニューラルネット構成でラベル付を行った方が精度がいい様に感じます。
私の過去記事にてひらがなを識別させるモデルの作成例を記載しているのできになる方は下記を参照ください。

ではみていきます。
SwiftyTesseractOCRを使用するpodファイル作成とインストール
podファイルの作成を行い、インストールするものを追加いたします。
pod init
Podfile作成されるので内容に追記
追記方法は普通にファイルを開いて追記かVimなどなんでもOK
追加事項は下記です。
pod 'SwiftyTesseract', '~> 2.0'
追記終われば下記でインストール
pod installこれでライブラリの追加はOKです。
Xcodeで作成されたworkspaceを開きます。
私はpod install とセットでコードで開いちゃいます。
open ~.xcworkspaceSwiftyTesseractOCRを使用するXcode側の設定
Xcodeを開いたら次はデータセットをプロジェクトに追加しましょう。
下記から必要な言語セット(今回は日本語なので)こちらのレポジトリの下記をクリックしてダウンロードページにて下記写真のものをダウンロード。
そのダウンロードしたものは「tessdata」というフォルダに入れてください。
.
└── tessdata
└── jpn-2.traineddata
このフォルダごと全てXcodeのプロジェクトに入れます。
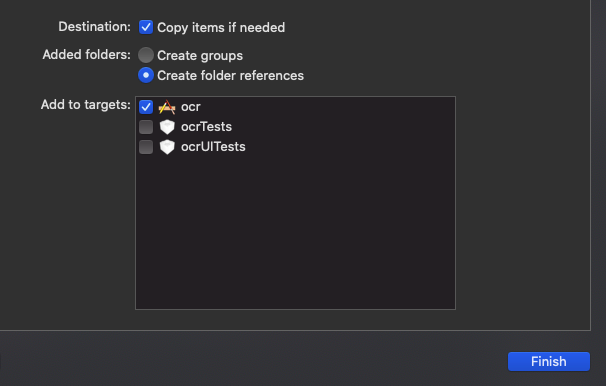
これと同じ様にjpg画像も同じ様にこちらは特にフォルダとかしていなく入れてしまいます。
これでOKです。
OCRライブラリ使用のソースコード紹介
次にSwiftyTesseractを使用するためのコードを記載していきます。
import UIKit
import SwiftyTesseract
class ViewController: UIViewController {
let swiftyTesseract = SwiftyTesseract(language: RecognitionLanguage.japanese)
@IBOutlet weak var ocrlabel: UILabel!
// デバイスからの入力と出力を管理するオブジェクトの作成
override func viewDidLoad() {
super.viewDidLoad()
ocrlabel.numberOfLines = 0
}
//OCR処理する画像(pngではなくjpg)
let filename1 = "IMG_0662.jpg”
@IBAction func Action1(_ sender: Any) {
guard let image = UIImage(named: filename1) else {
print("No")
return }
print(filename1)
swiftyTesseract.performOCR(on: image, completionHandler: { RecognitionLanguage in guard let text = RecognitionLanguage else { return }
print(text)
let ocrtext = text.trimmingCharacters(in: .whitespacesAndNewlines)
self.ocrlabel.text = ocrtext
} )
}
}上から順に見ていくと、まずライブラリのインポートがあり、インスタンス を作成。
そのご画像をUIIMageとして読み込むのですが、その際にpngでは私の環境では読み込めなかったため、jpgにて画像を読み込みました。たのネットの記事ではpngで読み取れている様なので正直なぞ。。
そしてOCR実行メソッドのperformOCRで実行すればOKです。
精度改善策について
結果に関してはなかなか難しい結果となりました。
そのため改善案としては画像をOCR処理する前に2値化するなど、グレースケール変換(もともとドキュメントからの読み取りがOCRの本領発揮なのでそこまで頑張って再現)、さらにいうなら文字領域の学習モデルを作成し文字領域検知と切り取りで文字情報のみをインプットするなどが精度向上に役立つとおもわれます。
実際にそれらの手法を試して比較した記事も要しているのできになる方はそちらをご参照ください。
実際にやってみた記事も後々紹介していきますが、おそらく自作のニューラルネット構築の方が手間が少なく楽にできる様な気がしてならない。。
まあでも画像を集める手間とかを考えると有用なのかも。
コメント
[…] 【Swift】SwiftyTesseractを使ってローカルjpg画像(日本語)にOCRする方法。 […]