今回の記事はscikit-learnを用いてロジスティック回帰で実データを分類する方法をご紹介します。初心者にも分かりやすいように記載しますので是非参考にしてみて下さい。
ロジスティック回帰用の実データの作成方法
まずはロジスティック回帰で使用するランダムな集合を作成してみます。下記のコードで実装できますので確認してみて下さい。
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from matplotlib import pyplot as plt
# データを用意する------------------------------------------
# 線形分離可能なデータセットを生成する
# クラス毎のデータ数
n = 20
# データフレーム初期化
df = pd.DataFrame()
# データ作成ループ
for i in range(2):
# ランダムなx値を計算
x = pd.Series(np.random.uniform(i, i + 1, n))
# ランダムなy値を計算
y = pd.Series(np.random.uniform(i, i + 1, n))
# ラベル(クラス)を作成
label = pd.Series(np.full(n, i))
# クラス毎のデータフレームを作成
temp_df = pd.DataFrame(np.c_[x, y, label])
# 作成されたクラス毎のデータを逐次結合
df = pd.concat([df, temp_df])
#作成したデータを訓練用とテスト用、正解データに分ける
# index(行ラベル)を初期化
df.index = np.arange(0, len(df), 1)
# クラス毎のデータフレームに分離(プロット用)
class_0 = df[df[2] == 0]
class_1 = df[df[2] == 1]
# 学習させる値(訓練データ)とクラス(正解ラベル)に分離
# 訓練データ
data = df[[0, 1]]
# 正解ラベル
data_class = pd.Series(df[2])作成したデータ数は20と指定しているんので20個のデータ分布からロジスティック回帰をscikit-learnで行ってもらいましょう。
では次に作成したデータでモデルを学習させていきましょう。
ロジスティック回帰のモデル作成
モデル作成もscikit-learnで簡易的に行うことができます。下記コードが学習する箇所です。
# ロジスティック回帰による学習
clf = LogisticRegression(C=1.0, solver='lbfgs')
clf.fit(data, data_class)上記のコードでモデルの学習が完了。この際に使用したデータは訓練用とテスト用に分けていたのでそれらを使用して結果をグラフにプロットしてみると下記のようになる。
# 決定境界可視化用
grid_line = np.arange(-5, 5, 0.05) # グリッドデータのための配列を生成
X, Y = np.meshgrid(grid_line, grid_line) # グリッドを作成
Z = clf.predict(np.array([X.ravel(), Y.ravel()]).T) # .predictが使えるデータshapeに変換して予測
Z = Z.reshape(X.shape) # 3Dプロットするためにshapeを再変換
r2 = clf.score(data1, data_class1) # 決定係数を算出
# フォントの種類とサイズを設定する。
plt.rcParams['font.size'] = 14
plt.rcParams['font.family'] = 'Times New Roman'
# 目盛を内側にする。
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
# グラフオブジェクトを定義する。
fig = plt.figure()
ax1 = plt.subplot(111)
# グラフの上下左右に目盛線を付ける。
ax1.yaxis.set_ticks_position('both')
ax1.xaxis.set_ticks_position('both')
# 軸のラベルを設定する。
ax1.set_xlabel('x')
ax1.set_ylabel('y')
# スケールの設定をする。
ax1.set_xlim(0, 2)
ax1.set_ylim(0, 2)
# データプロットする。
ax1.contourf(X, Y, Z, cmap='coolwarm')
ax1.scatter(class_0[0], class_0[1], label='class=0', edgecolors='black')
ax1.scatter(class_1[0], class_1[1], label='class=1', edgecolors='black')
ax1.text(0.1, 1.25, '$\ R^{2}=$' + str(round(r2, 2)), fontsize=20)
plt.legend()
# グラフを表示する。
plt.show()
plt.close()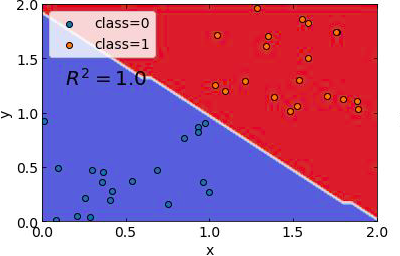
こちらが作成したデータに対しての結果になります。ではこのモデルに対して別のデータ分布を作成してみて結果を再度検証してみましょう。ちなみにここでモデルを保存しておきたい方もいると思うのでその場合は下記記事でscikit-learnのモデル保存・読み込み方法を記載しているのでそちらを合わせて参照ください。
「【scikit-learn】モデルの保存と読み込み方法。」
ロジスティック回帰で実データを分類
先ほどと同様の手法で今度はサンプルデータを40個分布させてみました。そのデータに対してモデル学習をさせず、先ほどのモデルを使いまわして検証を行いました。
# クラス毎のデータ数
n = 40
# データフレーム初期化
df1 = pd.DataFrame()
# データ作成ループ
for i in range(2):
# ランダムなx値を計算
x1 = pd.Series(np.random.uniform(i, i + 1, n))
# ランダムなy値を計算
y1 = pd.Series(np.random.uniform(i, i + 1, n))
# ラベル(クラス)を作成
label = pd.Series(np.full(n, i))
# クラス毎のデータフレームを作成
temp_df1 = pd.DataFrame(np.c_[x1, y1, label])
# 作成されたクラス毎のデータを逐次結合
df1 = pd.concat([df1, temp_df1])
# index(行ラベル)を初期化
df1.index = np.arange(0, len(df1), 1)
# クラス毎のデータフレームに分離(プロット用)
class_0 = df1[df1[2] == 0]
class_1 = df1[df1[2] == 1]
# 学習させる値(訓練データ)とクラス(正解ラベル)に分離
# 訓練データ
data1 = df1[[0, 1]]
# 正解ラベル
data_class1 = pd.Series(df1[2])
# 決定境界可視化用
grid_line = np.arange(-5, 5, 0.05) # グリッドデータのための配列を生成
X, Y = np.meshgrid(grid_line, grid_line) # グリッドを作成
Z = clf.predict(np.array([X.ravel(), Y.ravel()]).T) # .predictが使えるデータshapeに変換して予測
Z = Z.reshape(X.shape) # 3Dプロットするためにshapeを再変換
r2 = clf.score(data1, data_class1) # 決定係数を算出
# フォントの種類とサイズを設定する。
plt.rcParams['font.size'] = 14
plt.rcParams['font.family'] = 'Times New Roman'
# 目盛を内側にする。
plt.rcParams['xtick.direction'] = 'in'
plt.rcParams['ytick.direction'] = 'in'
# グラフオブジェクトを定義する。
fig = plt.figure()
ax1 = plt.subplot(111)
# グラフの上下左右に目盛線を付ける。
ax1.yaxis.set_ticks_position('both')
ax1.xaxis.set_ticks_position('both')
# 軸のラベルを設定する。
ax1.set_xlabel('x')
ax1.set_ylabel('y')
# スケールの設定をする。
ax1.set_xlim(0, 2)
ax1.set_ylim(0, 2)
# データプロットする。
ax1.contourf(X, Y, Z, cmap='coolwarm')
ax1.scatter(class_0[0], class_0[1], label='class=0', edgecolors='black')
ax1.scatter(class_1[0], class_1[1], label='class=1', edgecolors='black')
ax1.text(0.1, 1.25, '$\ R^{2}=$' + str(round(r2, 2)), fontsize=20)
plt.legend()
# グラフを表示する。
plt.show()
plt.close()結果は下記のようになっています。
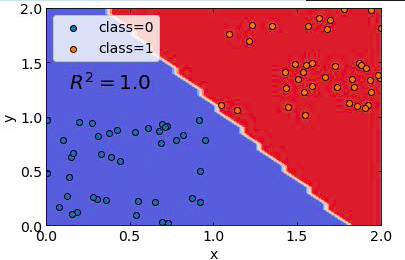
概ね分類できているように見えます。つまり、この分布に関して言えばこのロジスティック回帰で作成したモデルは有用と言えるということです。
では今回の記事は以上です。他にも多数の機械学習関連の記事を記載していますので是非そちらも興味があれば参考にしてみて下さい。
コメント